








LeViT
Imagenet classifier and general purpose backbone.
LeViT is a vision transformer model that can classify images from the Imagenet dataset.

Not supported
This model is currently not supported on any Automotive chipset.
To see performance metrics for this model on other chipsets, click the button below.
View for other chipsetsTechnical Details
Model checkpoint:LeViT-128S
Input resolution:224x224
Number of parameters:7.82M
Model size (float):29.9 MB
Model size (w8a16):8.83 MB
Applicable Scenarios
- Medical Imaging
- Anomaly Detection
- Inventory Management
License
Model:APACHE-2.0
Supported Automotive Devices
- SA7255P ADP
- SA8255P ADP
- SA8295P ADP
- SA8650P ADP
- SA8775P ADP
Supported Automotive Chipsets
- Qualcomm® SA7255P
- Qualcomm® SA8255P
- Qualcomm® SA8295P
- Qualcomm® SA8650P
- Qualcomm® SA8775P
Related Models
See all models

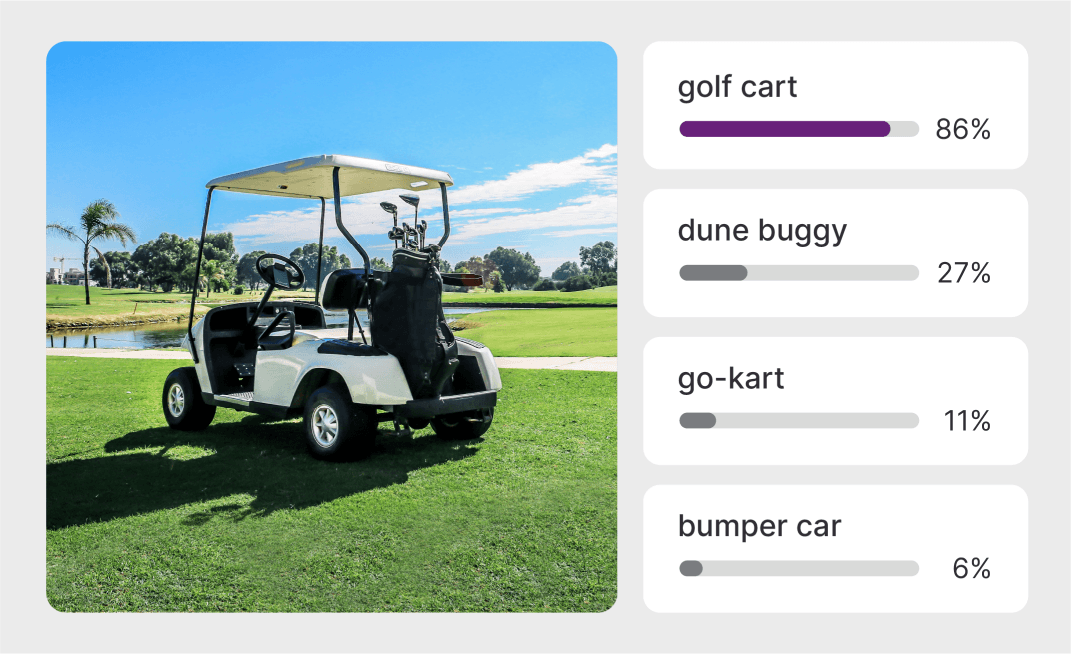
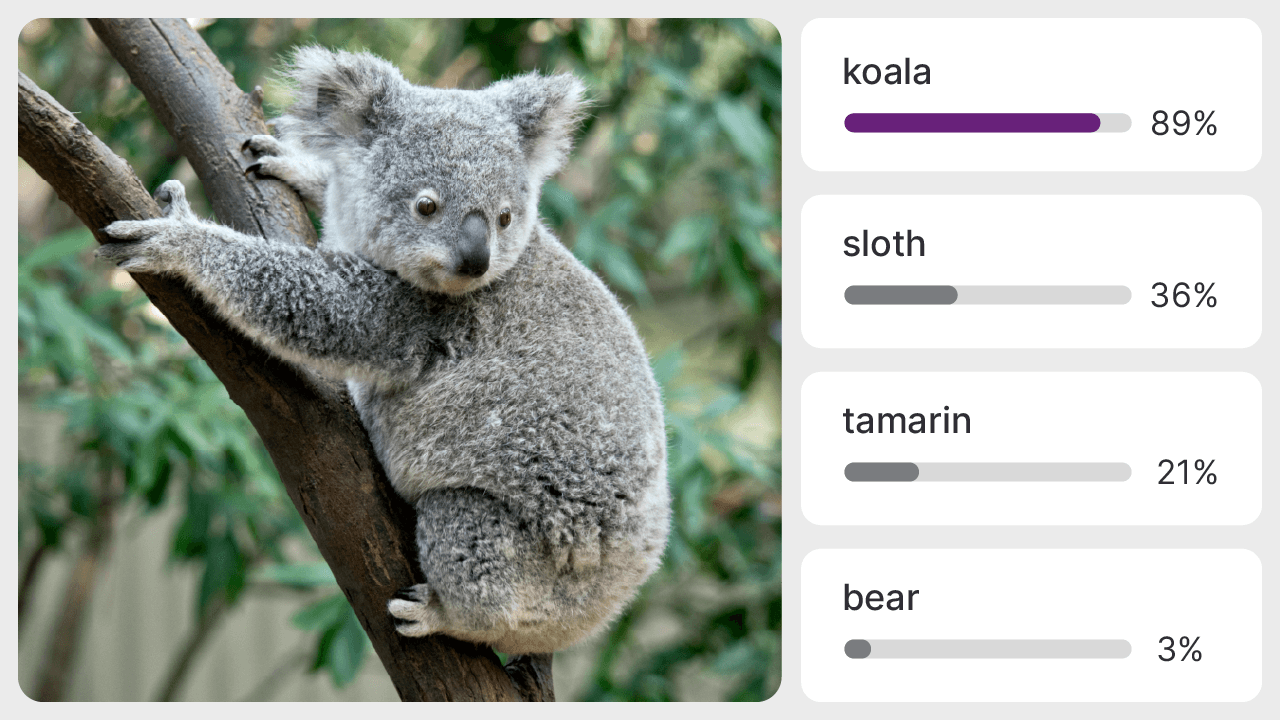
Looking for more? See models created by industry leaders.
Discover Model Makers