








On‑Device AI Starts Here
Start developing with Qualcomm® AI Hub
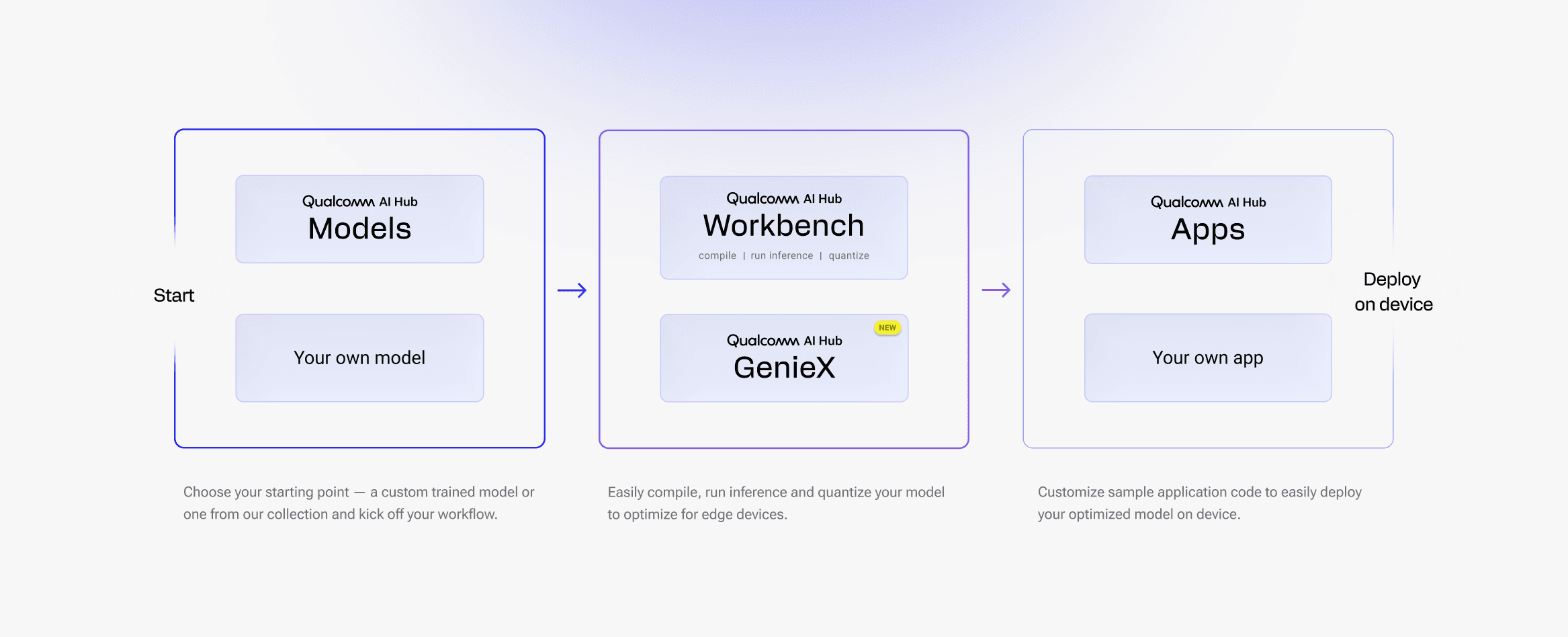
Qualcomm AI Hub is the place to optimize, validate, and deploy any model in a few lines of code for Qualcomm devices. Our four products can be used independently or together as part of your on-device development workflow.
Follow the walkthrough that best fits your needs:
Getting started with Qualcomm® AI Hub GenieX. Run frontier language and vision-language models locally on Hexagon NPU, Adreno GPU, or CPU with a few lines of code, using the llama.cpp or QAIRT plugin that best fits your deployment.
Getting started with Qualcomm® AI Hub Models. Browse and download pre-optimized models covering vision, speech, audio, and text applications, validated on Qualcomm® chipsets.
Getting started with Qualcomm® AI Hub Apps. Clone and customize sample application code for bundling a model to deploy on-device. Filter by domain, operating system, and more.
Getting started with Qualcomm® AI Hub Workbench. Optimize your custom trained model for a target runtime, run inference, and profile on-device performance with a few lines of code. Target 50+ hosted Qualcomm devices, provisioned within minutes.

Account Setup
To use AI Hub Workbench and export certain models from AI Hub Models, you will first need to create a Qualcomm ID and authenticate with your AI Hub API token.
Create a Qualcomm ID
If you already have a Qualcomm ID, skip this step and use your credentials to log into AI Hub Workbench. Otherwise, navigate to the Qualcomm ID sign up page and follow these steps:
- Fill in your information
- Verify your email address
- Choose your work location
At this point, you will be signed in and directed to your Qualcomm ID Profile page.
Authenticate with AI Hub
Navigate to your Workbench Account Settings page. Open a terminal window to complete the rest of your setup:
Install the qai-hub package via PyPi:
pip3 install qai-hubRun the following command with the API token from your Settings page:
qai-hub configure --api_token API_TOKENVerify your token setup by listing the devices we support:
qai-hub list-devices
Now you're ready to get started!