








InternImage
InternImage Large‑Scale Vision Foundation Model.
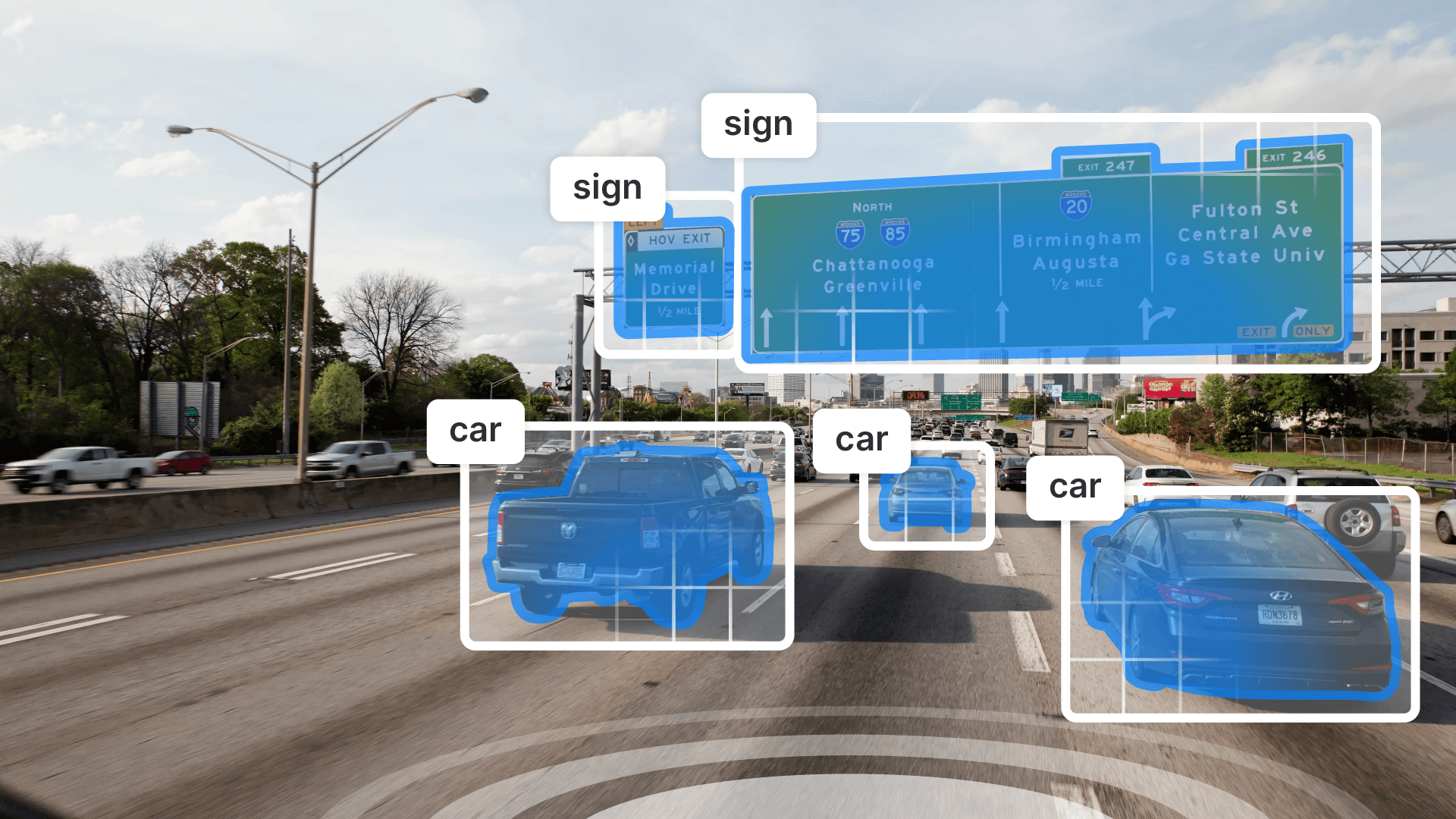
InternImage employs DCNv3 as its core operator to equips the model with dynamic and effective receptive fields required for downstream tasks like object detection and segmentation, while enabling adaptive spatial aggregation.
Not supported
This model is currently not supported on any Compute chipset.
To see performance metrics for this model on other chipsets, click the button below.
View for other chipsetsTechnical Details
Model checkpoint:internimage_t_1k_224
Input resolution:1x3x224x224
Number of parameters:30.6M
Model size (float):117 MB
Applicable Scenarios
- Self driving cars
License
Model:MIT
Supported Compute Devices
- Snapdragon X Elite CRD
- Snapdragon X Plus 8-Core CRD
- Snapdragon X2 Elite CRD
Supported Compute Chipsets
- Snapdragon® X Elite
- Snapdragon® X Plus 8-Core
- Snapdragon® X2 Elite
Looking for more? See models created by industry leaders.
Discover Model Makers