








Video-MAE
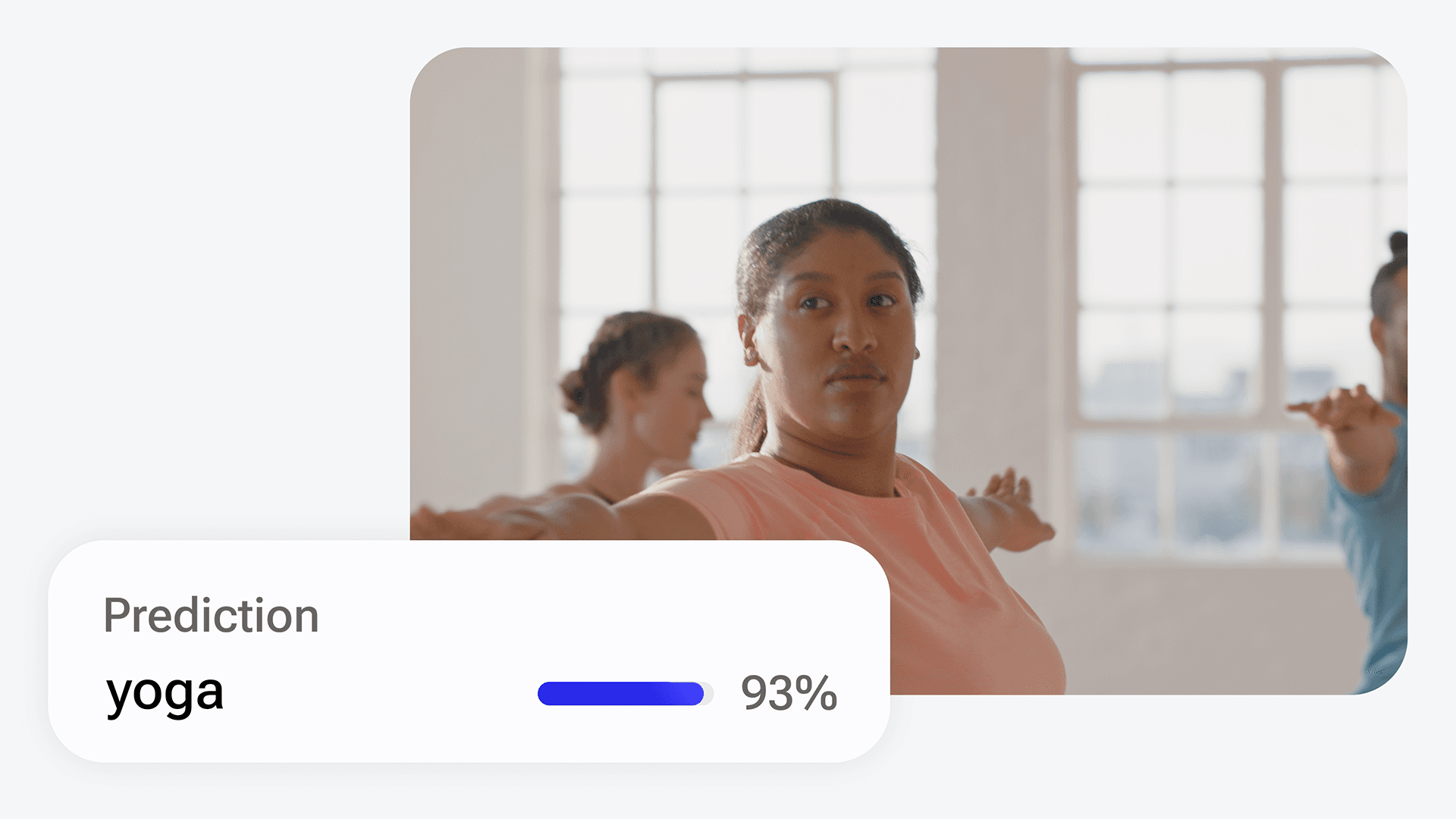
Sports and human action recognition in videos.
Video MAE (Masked Auto Encoder) is a network for doing video classification that uses the ViT (Vision Transformer) backbone.
Not supported
This model is currently not supported on any IoT chipset.
To see performance metrics for this model on other chipsets, click the button below.
View for other chipsetsTechnical Details
Model checkpoint:Kinectics-400
Input resolution:224x224
Number of parameters:87.7M
Model size (float):335 MB
Applicable Scenarios
- Camera
- Action Recognition
License
Model:CC-BY-4.0
Tags
- backbone
Supported IoT Devices
- Dragonwing IQ-9075 EVK
- Dragonwing IQ-X5121
- Dragonwing IQ-X7181
- Dragonwing Q-8750
- QCS8550 (Proxy)
Supported IoT Chipsets
- Qualcomm® QCS7181
- Qualcomm® QCS8550 (Proxy)
- Qualcomm® QCS8750
- Qualcomm® QCS9075
Related Models
See all models
Looking for more? See models created by industry leaders.
Discover Model Makers