








OpenAI-Clip
Multi‑modal foundational model for vision and language tasks like image/text similarity and for zero‑shot image classification.
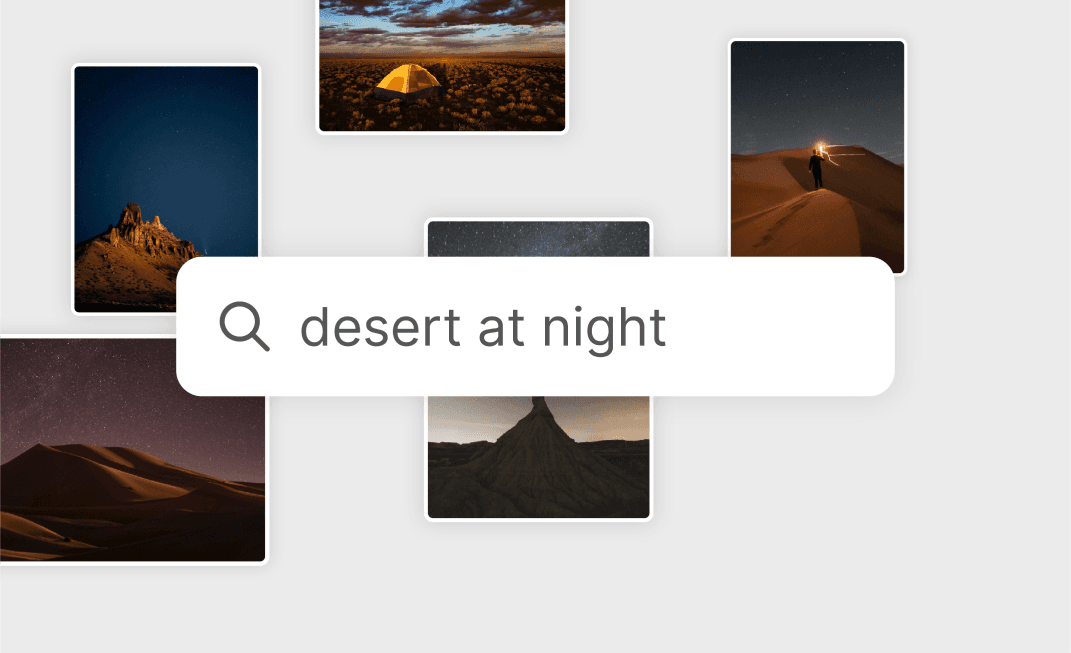
Contrastive Language‑Image Pre‑Training (CLIP) uses a ViT like transformer to get visual features and a causal language model to get the text features. Both the text and visual features can then be used for a variety of zero‑shot learning tasks.
Not supported
This model is currently not supported on any All Models chipset.
To see performance metrics for this model on other chipsets, click the button below.
View for other chipsetsTechnical Details
Model checkpoint:ViT-B/16
Image input resolution:224x224
Text context length:77
Number of parameters:150M
Model size (float):571 MB
Applicable Scenarios
- Image Search
- Content Moderation
- Caption Creation
Supported Form Factors
- Phone
- Tablet
License
Model:MIT
Tags
- foundation
Supported Devices
- Dragonwing IQ-8275 EVK
- Dragonwing IQ-9075 EVK
- Dragonwing IQ-X5121
- Dragonwing IQ-X7181
- Dragonwing Q-8750
- QCS8550 (Proxy)
- SA7255P ADP
- SA8255P ADP
- SA8295P ADP
- SA8650P ADP
- SA8775P ADP
- Samsung Galaxy S21
- Samsung Galaxy S21 Ultra
- Samsung Galaxy S22 5G
- Samsung Galaxy S22 Ultra 5G
- Samsung Galaxy S22+ 5G
- Samsung Galaxy S23
- Samsung Galaxy S23 Ultra
- Samsung Galaxy S23+
- Samsung Galaxy S24
- Samsung Galaxy S24 Ultra
- Samsung Galaxy S24+
- Samsung Galaxy S25
- Samsung Galaxy S25 Ultra
- Samsung Galaxy S25+
- Samsung Galaxy S26
- Samsung Galaxy S26 Ultra
- Samsung Galaxy S26+
- Samsung Galaxy Tab S8
- Snapdragon 8 Elite Gen 5 QRD
- Snapdragon 8 Elite QRD
- Snapdragon X Elite CRD
- Snapdragon X Plus 8-Core CRD
- Snapdragon X2 Elite CRD
- Xiaomi 12
- Xiaomi 12 Pro
- XR2 Gen 2
Supported Chipsets
- Qualcomm® Dragonwing™ IQ-X7181
- Qualcomm® QCS8275
- Qualcomm® Dragonwing™ QCS8550 (Proxy)
- Qualcomm® Dragonwing™ Q-8750
- Qualcomm® Dragonwing™ IQ-9075
- Qualcomm® SA7255P
- Qualcomm® SA8255P
- Qualcomm® SA8295P
- Qualcomm® SA8650P
- Qualcomm® SA8775P
- Snapdragon® 8 Elite Mobile
- Snapdragon® 8 Elite Gen 5 Mobile
- Snapdragon® 8 Gen 1 Mobile
- Snapdragon® 8 Gen 2 Mobile
- Snapdragon® 8 Gen 3 Mobile
- Snapdragon® 888 Mobile
- Snapdragon® X Elite
- Snapdragon® X Plus 8-Core
- Snapdragon® X2 Elite
Looking for more? See models created by industry leaders.
Discover Model Makers